

INDICE
La chiamata arriva in un pomeriggio d’inverno, quando il SOC sembra quasi addormentato.
Una dashboard si accende di rosso: picchi di connessioni brevissime sulla 27017, la porta di MongoDB. Nessun utente autenticato, nessun client noto, eppure il traffico cresce come una marea.
Qualche minuto dopo iniziano a comparire nei log messaggi strani, errori di parsing da pacchetti compressi. L’analista del Blue Team stringe la tazza di caffè: “È MongoBleed?”.
Non è un nome a caso: come Heartbleed una decade fa, anche qui si parla di memoria che “sanguina”, solo che stavolta a farlo è MongoDB, uno dei database più usati al mondo. La falla ha un nome preciso, CVE‑2025‑14847, ed è già sfruttata in the wild con PoC pubblici e campagne di scanning di massa (fonti: Akamai, Unit 42, BleepingComputer, SecurityWeek, DarkReading).
Cosa succede, in parole semplici
MongoDB supporta la compressione zlib dei messaggi di rete per risparmiare banda. L’attaccante invia un pacchetto compresso e malformato, gonfiando un numero che dice al server quanto sarà grande il messaggio una volta decompresso. MongoDB alloca un buffer troppo grande e, per come gestisce quell’errore, rimanda indietro parti di memoria non inizializzata.
In quei frammenti possono comparire password in chiaro, token, API key, pezzi di documenti o configurazioni. E il tutto avviene prima dell’autenticazione: basta raggiungere la porta del DB.
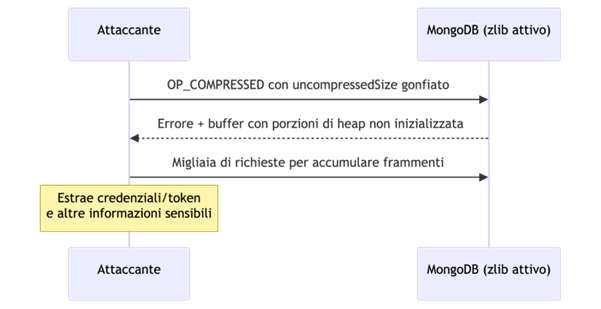
Mini‑schema – Sequenza dell’attacco
Com’è possibile “leggere” la memoria
Il problema, che in certi casi porta il server a restituire per errore frammenti della propria memoria, nasce da una gestione difettosa delle richieste compresse e delle allocazioni, con conseguenze che vanno oltre un semplice crash applicativo.
Quando il server riceve richieste compresse malformate, il processo di decompressione calcola in modo errato la dimensione dei buffer da allocare in memoria. Questo porta a un’allocazione eccessiva (oversized allocation) oppure a un uso improprio dei buffer.
Se, a seguito di questo errore, il server genera una risposta di errore, quest’ultima può includere dati residui presenti nella heap, cioè porzioni di memoria che: non appartengono alla richiesta effettuata, contengono dati di operazioni precedenti, non sono state inizializzate/ripulite correttamente. In pratica, l’attaccante non “legge” la memoria direttamente, ma spinge il server a restituirgliela involontariamente all’interno della risposta.
L’immagine sottostante rappresenta il flusso concettuale di MongoBleed: richiesta compressa → allocazione esagerata → risposta d’errore con porzioni di heap.
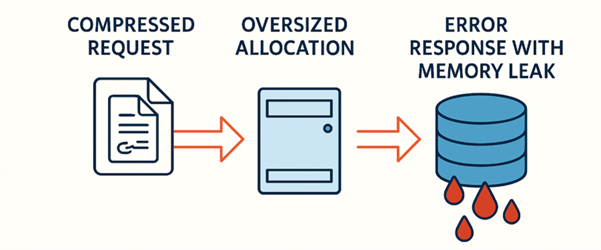
Flusso concettuale di MongoBleed
Versioni colpite & fix
Alla pubblicazione del PoC (fine dicembre), il tempo tra disclosure e sfruttamento attivo è stato di pochi giorni. Le stime parlano di decine di migliaia di istanze esposte su Internet e bersagliate da scansioni automatiche. In alcuni casi, i ricercatori hanno visto trapelare password del DB, chiavi cloud e dettagli di container e WiredTiger.
Lato Blue Team sono comparsi strumenti di detection dedicati (ad es. un Velociraptor artifact e il MongoBleed Detector di Florian Roth) che analizzano log e telemetrie FTDC alla ricerca di pattern compatibili con l’exploit. (Fonti: Substack – Eric Capuano, Heise)
MongoDB ha rilasciato patch: 4.4.30, 5.0.32, 6.0.27, 7.0.28, 8.0.17, 8.2.3. Le versioni 3.6/4.0/4.2 sono EoL. Nessuna patch: serve migrare. (Fonti: Tenable, BleepingComputer).
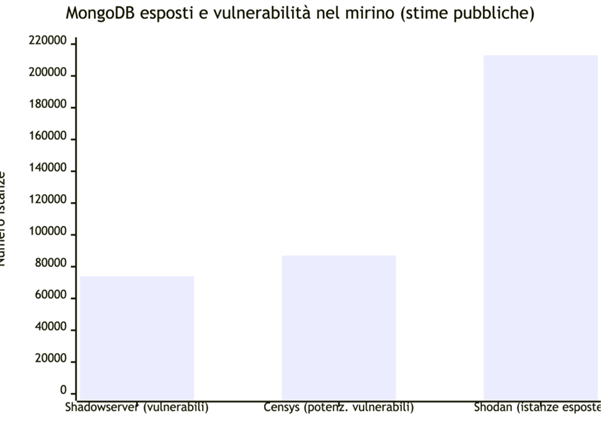
Nota: i numeri provengono da rilevazioni pubbliche in momenti diversi e con metodologie differenti; vanno letti come ordini di grandezza dell’esposizione. (Fonti: Techworm/CISA, Akamai)
Cosa fare subito (checklist “a caldo”)
1) Riduci la superficie d’attacco
- Blocca l’esposizione a Internet: limita la 27017 a soli host applicativi; in container non pubblicare 0.0.0.0:27017.
2) Mitiga il codice vulnerabile
- Aggiorna a 4.4.30 / 5.0.32 / 6.0.27 / 7.0.28 / 8.0.17 / 8.2.3.
- Se non puoi aggiornare subito, disabilita zlib (es. net.compression.compressors: snappy,zstd). Possibile lieve impatto prestazionale, ma rimuovi il percorso vulnerabile.
# mongod.conf
net:
compression:
compressors: snappy,zstd # ometti "zlib" 3) Assumi il peggio e ruota i “secrets”
- Tratta password DB, segreti app e chiavi cloud come potenzialmente esposti: rotali appena chiusa la falla. È una raccomandazione esplicita in più advisory.
4) Caccia agli indizi
- Centralizza i log di MongoDB e cerca picchi di connessioni effimere senza metadata/driver ed errori su messaggi compressi.
- Analizza FTDC e serverStatus.asserts (valori “user” anomali). Strumenti utili: Velociraptor artifact e MongoBleed Detector.
Dopo l’emergenza: rendere il DB noioso (cioè sicuro)
- Autenticazione forte (SCRAM) e TLS ovunque; niente accessi anonimi o legacy.
- Principio del minimo privilegio per utenti/ruoli; audit degli account dormienti.
- Micro‑segmentazione tra tier app/DB e regole esplicite est‑ovest; monitora costantemente la 27017.
- Patch management con finestre brevi: MongoBleed ha mostrato quanto sia corto il tempo tra annuncio e sfruttamento.
FAQ lampo
- È una RCE? No: è una information disclosure. Ma i dati rubati possono facilitare compromissioni successive.
- Atlas è al sicuro? I cluster Atlas sono stati patchati automaticamente; il rischio maggiore è nei self‑hosted: verifica, comunque, la versione e le impostazioni.
- Come riconosco uno sfruttamento? Log con errori su pacchetti compressi, molte connessioni brevi senza metadata/driver, asserts anomali e (in alcuni casi) risposte insolitamente corpose.
Conclusioni
La lezione di MongoBleed è semplice: i database non amano stare sotto i riflettori di Internet.
Chiudi le tende (segmentazione), cura la dieta (patch), evita le cattive compagnie (compressioni vulnerabili) e, se pensi che qualcuno abbia già sbirciato, cambia le chiavi di casa.
Vuoi una verifica concreta del tuo livello di esposizione? Contattaci attraverso la nostra pagina dedicata per confrontarti con il nostro team di sicurezza e capire come proteggere davvero il tuo database da vulnerabilità come MongoBleed.